随着近年来 AI 技术的兴起,视频监控、汽车、智能家居、移动设备及数据中心等对高清视频处理有了越来越高的要求。安谋科技全新视频处理器 ——“玲珑” V6/V8,针对主流市场的视频流媒体技术进行了大量投入,通过一系列智能权衡实现了极大优化,为所有合作伙伴提供灵活的组合和选择。LiveVideoStackCon 2022 北京站邀请到了安谋科技多媒体产品经理董峰,为我们分享 “玲珑” 编解码融合架构助力视频多元化需求。
文 / 董峰
编辑 / LiveVideoStack

此次是安谋科技在 LiveVideoStack 大会的演讲首秀。安谋科技是中国最大的芯片 IP 设计与服务供应商,在立足全球生态、深耕本土创新的基础上,坚持以自研 IP 技术的创新发展与 Arm IP 相配合,为本土集成电路产业提供丰富的产品组合和解决方案。
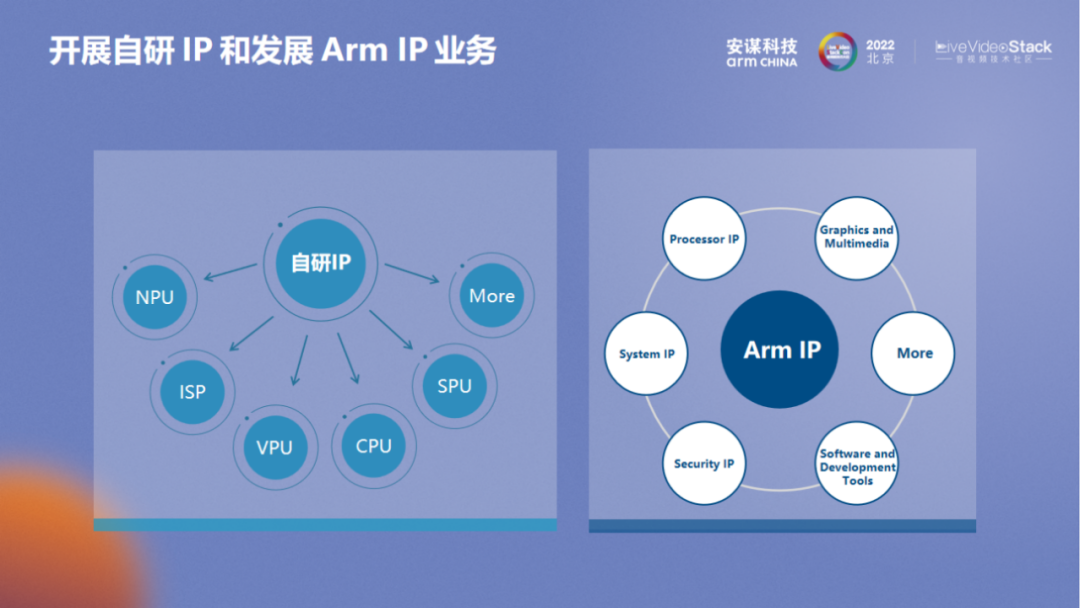
自 2018 年独立运营以来,安谋科技坚持开展自研 IP 和发展 Arm IP 业务,一方面是结合中国市场需求积极布局自研业务,坚持 “全球标准,本土创新”,陆续推出 “周易” NPU、“星辰” CPU、“山海” SPU 以及 “玲珑” ISP&VPU 等自研 IP 成果,并全部实现了客户相关芯片产品的流片和量产。另一方面,安谋科技也致力于将 Arm 先进的架构和技术引进国内,满足国内公司开发具有全球竞争力产品的需求。在两大支柱业务的合力之下,目前安谋科技已打造一体化、完整的异构计算 IP 核心矩阵,助力中国智能计算产业高速发展。


芯片 IP 厂商需要考虑多元化的需求,应当满足不同场景下的不同诉求。对于视频来说,无论是端、边、云都有很大的视频编解码需求。端侧手机、IPC、无人机等不同场景对视频编解码的需求存在较大差异。而云端和车载则是完全不同的方向。手机以及安防在编码和解码方面差异也较为明显,手机客户解码需求更强,但是旗舰机对于一些图传也存在不同需求。作为 IP 厂商如何面对复杂多变的市场需求是首当其冲的问题。
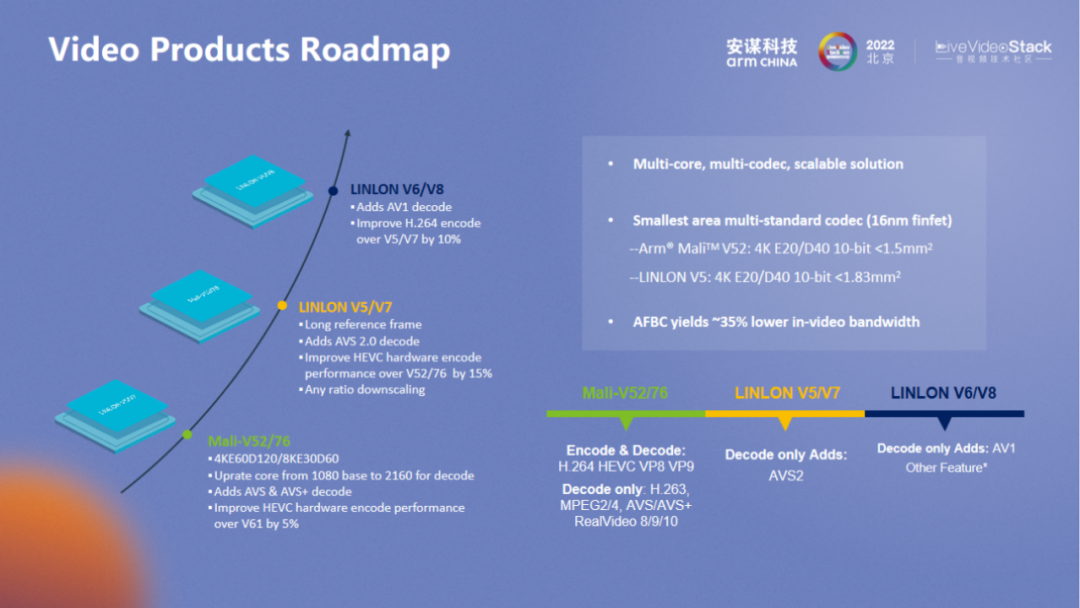
安谋科技 VPU 团队在 2019 年底成立,从 2020 年初开始研发自研产品。我们团队从 Arm Mali-V52 的维护开始,逐渐完成两代产品的研发。为了更好地满足行业基本格式需求,我们新增了 AVS2 和 AV1 格式,“玲珑” V5/V7 花费了近三个季度完成,“玲珑” V6/V8 则花费了将近一年。除了增加格式之外,还增强了整体编码能力。“玲珑” V5/V7 的 HEVC 编码质量与 Arm Mali-V52/76 相比提升了 15%,“玲珑” V6/V8 的 H.264 编码质量也比 “玲珑” V5/V7 提升了 10%。面对多样的产品需求,增加了复杂的前后处理,“玲珑” V5/V7 增加了 Any ratio downscaling 的后处理;“玲珑” V6/V8 增加了 OSD 的前处理,以及 YUV 到 RGB 的后处理。
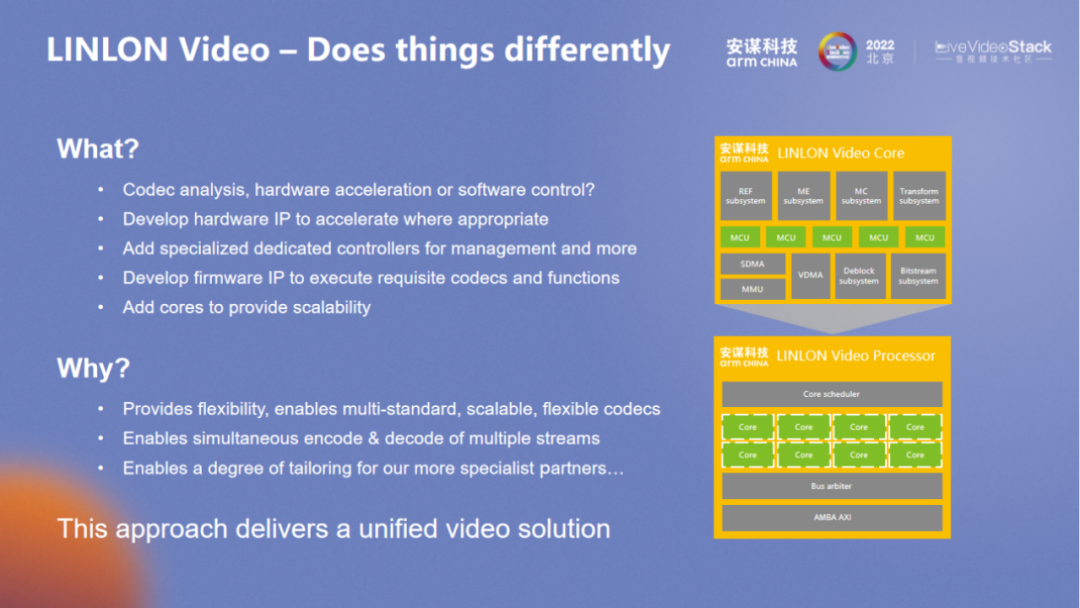
“玲珑” VPU 支持全格式,整体面积较小。“玲珑” V5 全格式支持包括前后处理 P&R 之后是 1.83。芯片 IP 行业一直在追求更高的性能、更小的功耗和更小的面积,产品在迭代过程中针对上述问题的改进还是颇有成效。在整体架构方面也有别于其它架构,“玲珑” VPU 以单核实现编解码融合,既可以编码也可以解码,以适用于多样场景的需求。不只是硬件格式的支持,还囊括了可编程的软件部分,以满足对多种场景变化的需求。
在硬件层面上,“玲珑” VPU 添加更多灵活可配的接口,其它能力通过软件层面实现扩展。该产品整体是 5 个 MCU 的结构,不同的 MCU 对应控制不同的硬件加速器。在 spec 分析阶段,需要考虑哪些可以固化、哪些可以通过灵活的软件配置实现,再将可固化的部分做成纯硬件。
尽管端和云对处理器性能要求差异巨大,但是从芯片 IP 角度出发,还是希望能用统一的方式来支撑不同场景的需求,基于多核的可拓展性对性能进行扩展,通过扩展核数以支持不同场景需求。例如,端侧客户单核即可满足需求,而边缘侧大致需要四核,那云端基本需要八核。在 7nm 制程前提下,八核基本可以实现 8k@60fps 编码或 8k@120fps 解码。
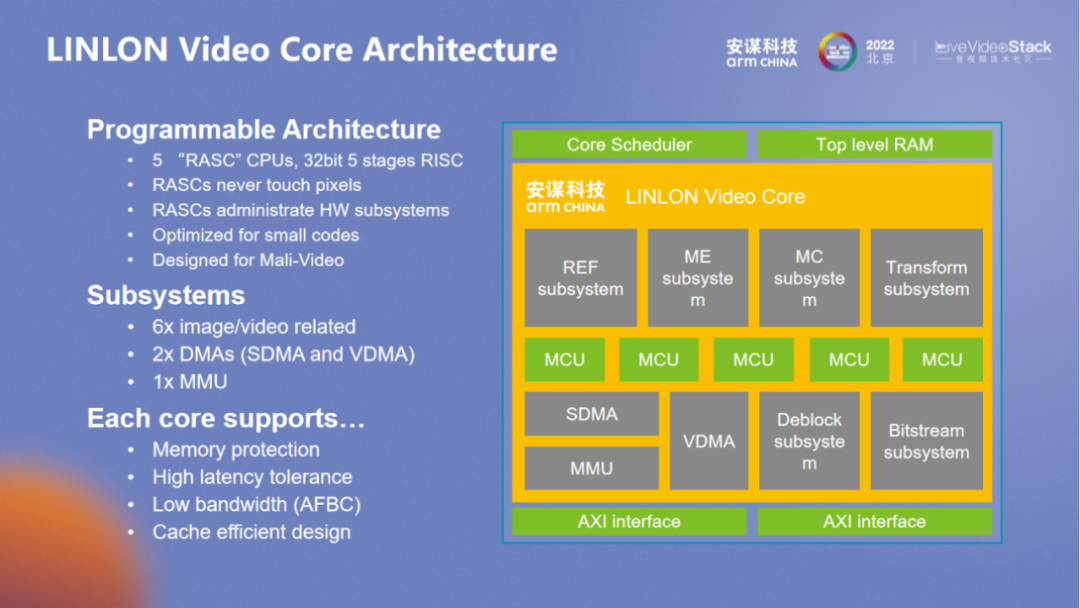
除了上述的多核可拓展性之外,“玲珑” VPU 对于 MCU 本身也会有所考量。不同于 Arm Cortex A 和 Cortex M 的核,其单独为视频场景进行定制优化,基本上仍然是 5 级的流水。而在频率方面,和整个 VPU 同频。16FF 下至少可达到 800MHz。由此可见,该核本身就可以保证其性能,在视频场景下更侧重于加速器的控制,所以不会让其触碰 pixel 内容,在指令集方面也做了很多优化。
除了 6 个加速器之外,“玲珑” VPU 还有两个 DMA 相关的单元,一个是 SDMA,另一个是 VDMA。VDMA 主要用于处理 Frame 级别的数据,包括编码的输入数据和解码的输出数据,前后处理也可以通过该单元灵活扩展。这几代产品的迭代都是把功能分散到不同的加速器以及 top 层上。应对不同场景的需求,除了性能和基本功能之外,系统层面仍然有差异化的需求,多路的隔离、系统访存延迟优化、降带宽、降延时等都属于系统层面的优化,也和 Arm 的生态保持一致。
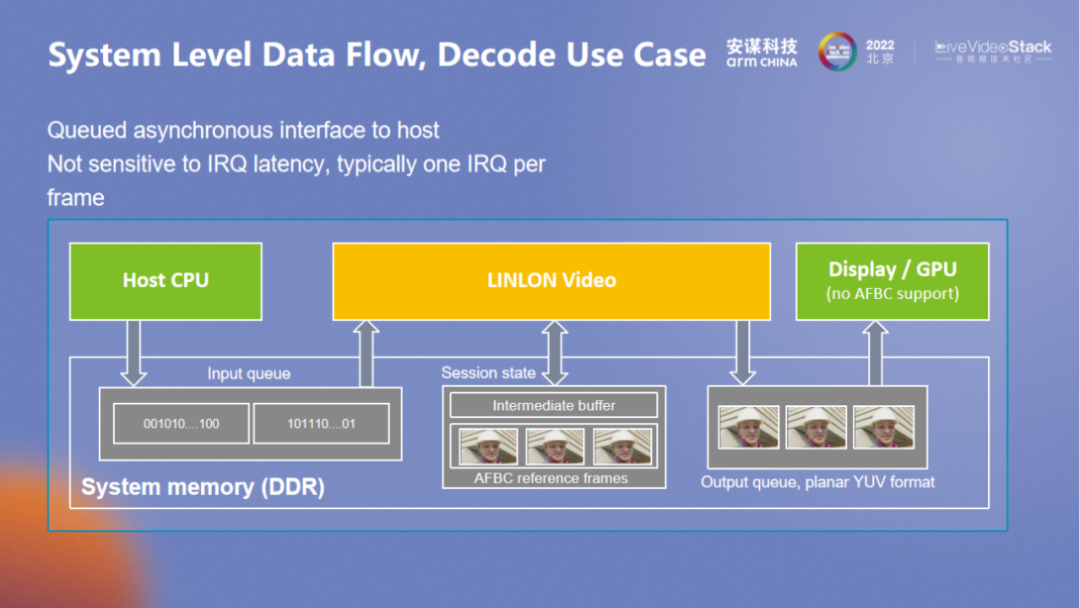
在系统层面,通过降带宽、降延时来应对大带宽系统的需求,基于 AFBC,可与 Arm GPU 以及 Display 搭配进行,内部中间的参考帧使用 AFBC 压缩,可让带宽在输入和输出都不压缩的情况下降低 35%。在 GPU 使用 VPU 解码数据进行纹理渲染时,整体的带宽可降低至原先的 45%。在 Display 场景中,也可以达到类似的效果。除了整个数据流,中间的参考帧数据也可以单独拿出来为后面的单元进行相对地管理,也可以有效降低带宽。“玲珑” VPU 围绕各个层面进行统一考量,以更好地降低带宽需求。
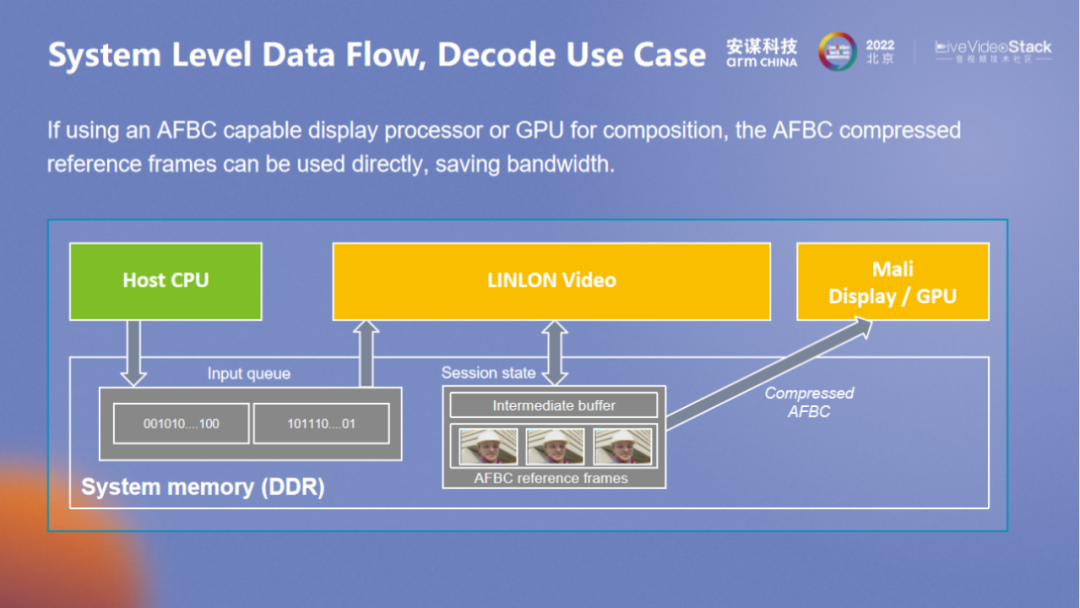
VPU 不仅需要在视频场景中考量系统层面的优化,也需要从系统层面进行考量,内部的并行也可以在 top ram 进行优化,以减少多核之间的内存访存。VPU 与 CPU 处理器、视频、显示的联合也可以做到类似的效果。
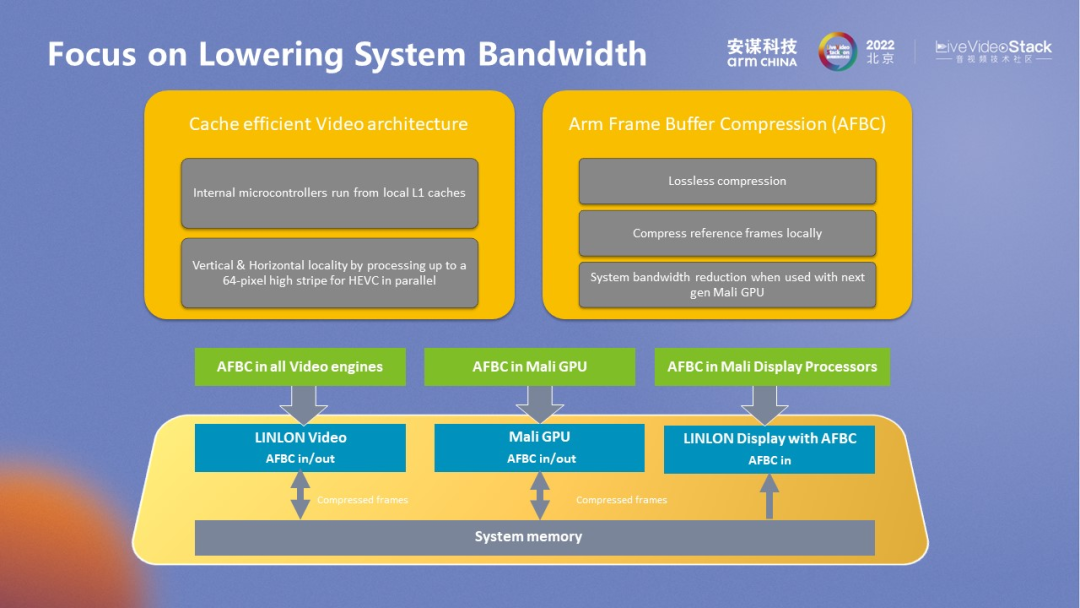
就 AFBC 本身而言,也分为不同的版本。AFBC 是 Arm Frame Buffer Compression 的缩写,简单理解就是 Arm 系统层面上的无损压缩,主要目的是带宽的优化。AFBC 的能力是基于 Arm 整个 IP 层面来实现的,是在系统层面的整体优化。对于 ISP 而言,Arm 也有专用的 AFBC 模块用来连接 ISP,端侧场景也可以在视频里直接输入 AFBC 数据以减少带宽。AFBC 的好处很多,尤其是对 rotation 十分友好,系统层面通过 AFBC 就可以绕过 rotation 这种耗带宽的处理,从原始数据进行 rotation 的访问,对于系统的总线来说存在不小的压力。但通过 AFBC 的方式在内部优化 rotation,能够支持连续的访问,这种方式更简单高效。此外,AFBC 的不同格式也对系统的随机访问有所支持。
“玲珑” VPU 原生就支持多路,端侧场景也需要多路,对于云端场景来说多路更是刚需。应对多路复杂多分辨率的场景,也是巨大的考验。“玲珑” VPU 通过核心调度器负责多核调度,多核并行按照条带级别划分任务,任何核都可以通过核心调度器硬件直接调度。“玲珑” VPU 原生硬件可支持 4 个上下文,4 路不同场景都可以通过核心调度器进行切换。而总线仲裁器则负责系统层面的访问,与核互联以整体判决,从而优化缓存,在输出时可通过 AXI 进行。三步结合,一起对访存进行优化。
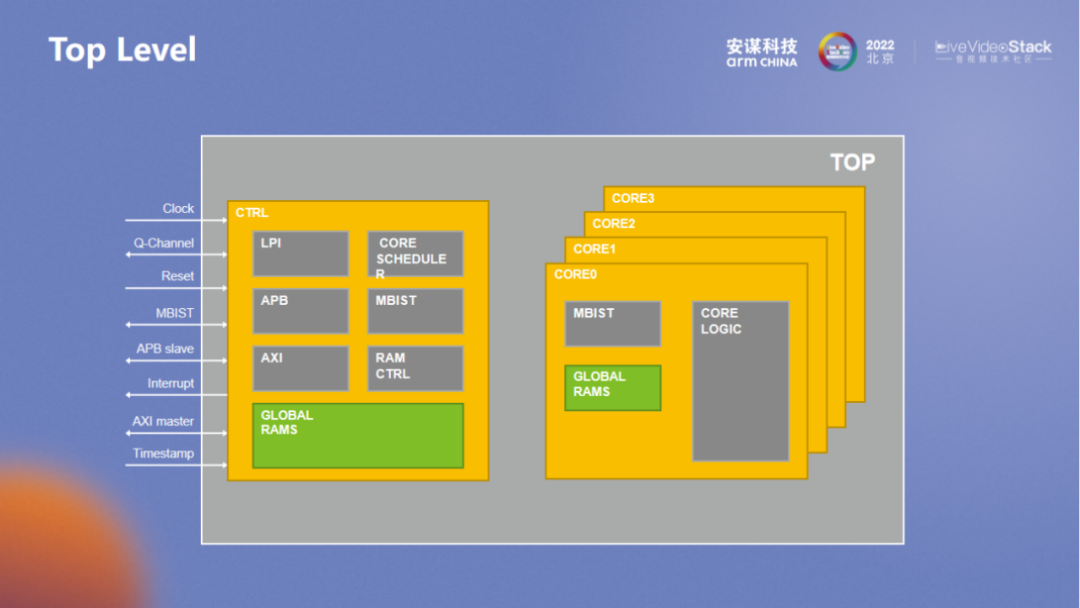
为应对云端和边缘场景,除了对核进行优化之外,硬件也要进行优化。低功率可以通过 LPI 接口得以实现。整体来看,多核、异步处理是优化过程中的核心部分。不同的要求可以使用不同的管理策略,灵活配置能够更好地服务客户。
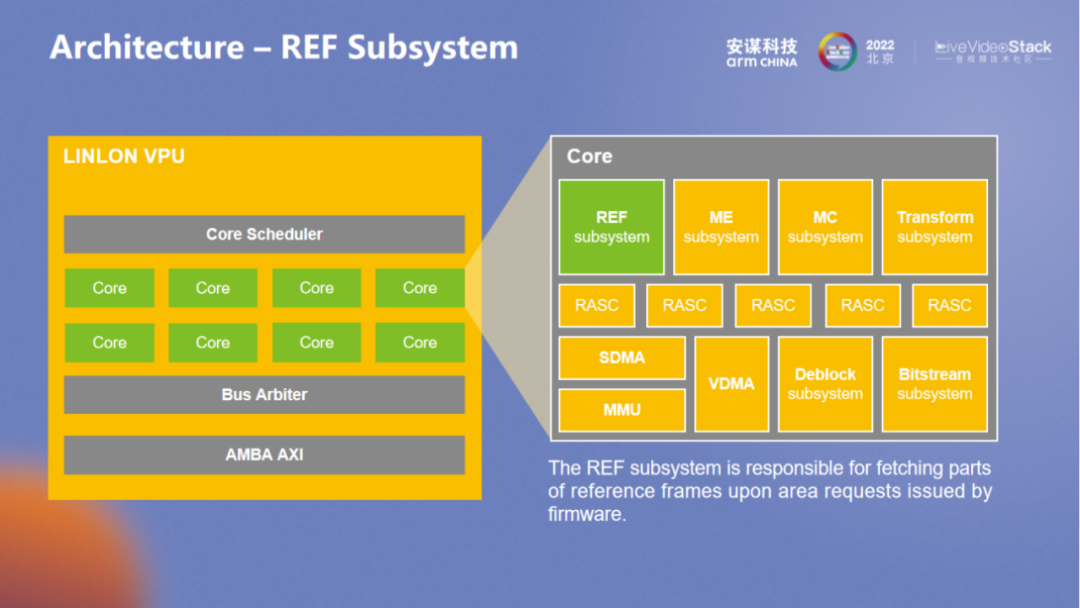
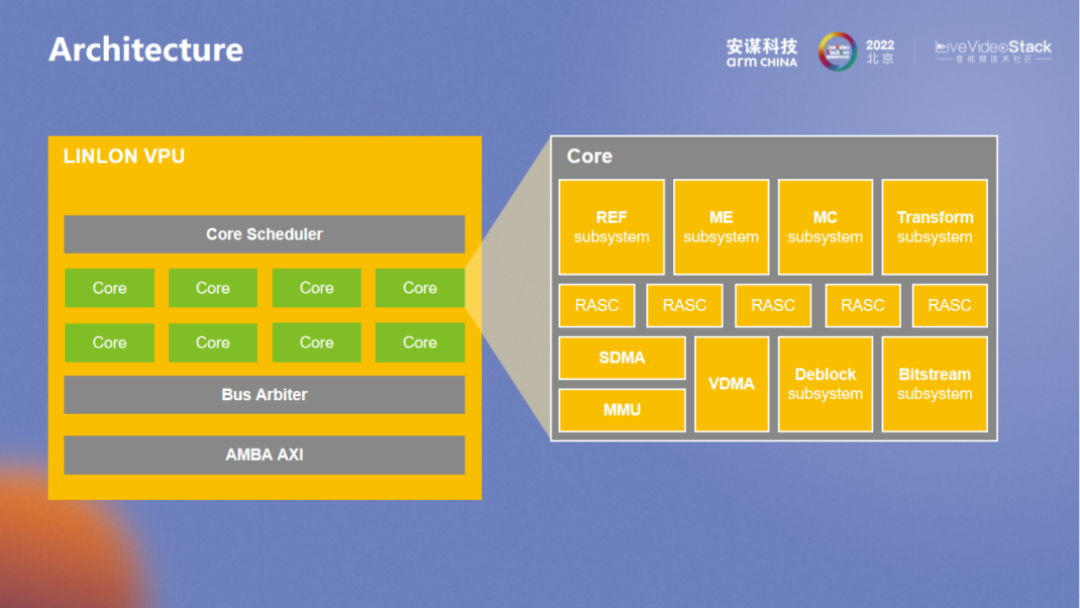
REF 主要用于处理参考帧的访问,可通过随机访问以达到性能的优化。
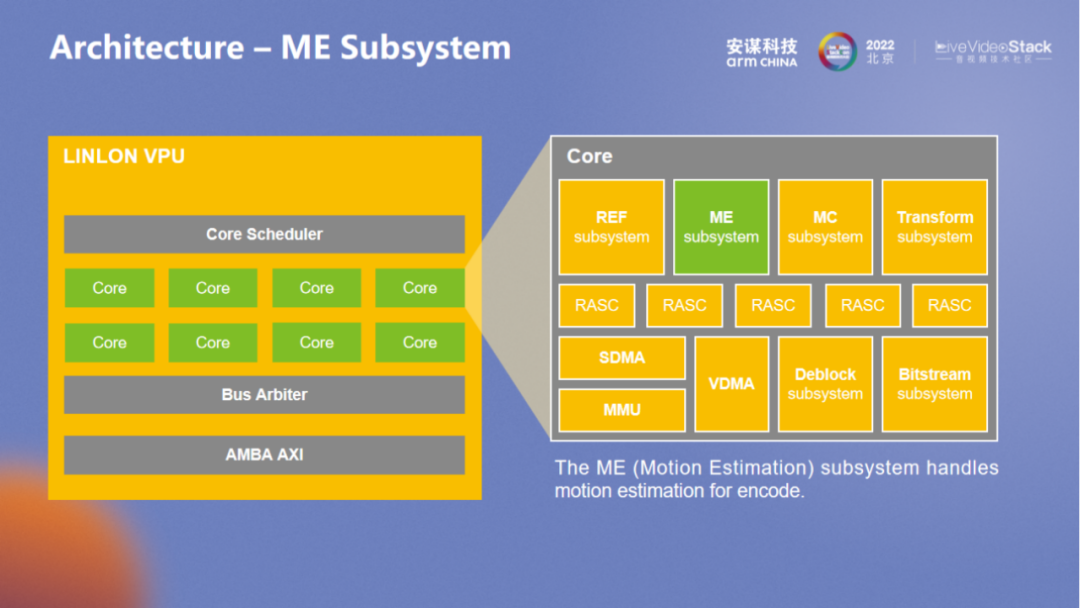
“玲珑” VPU 内部的算法十分灵活,ME 的目标也很灵活。产品编码的迭代更多是在 ME 层面上实现。
“玲珑” VPU 架构里的软件控制同样灵活,面对相应的需求可及时调整。实力强劲的厂商也可以使用自己的 ME。对于 ME 的接口开放也是非常灵活的。
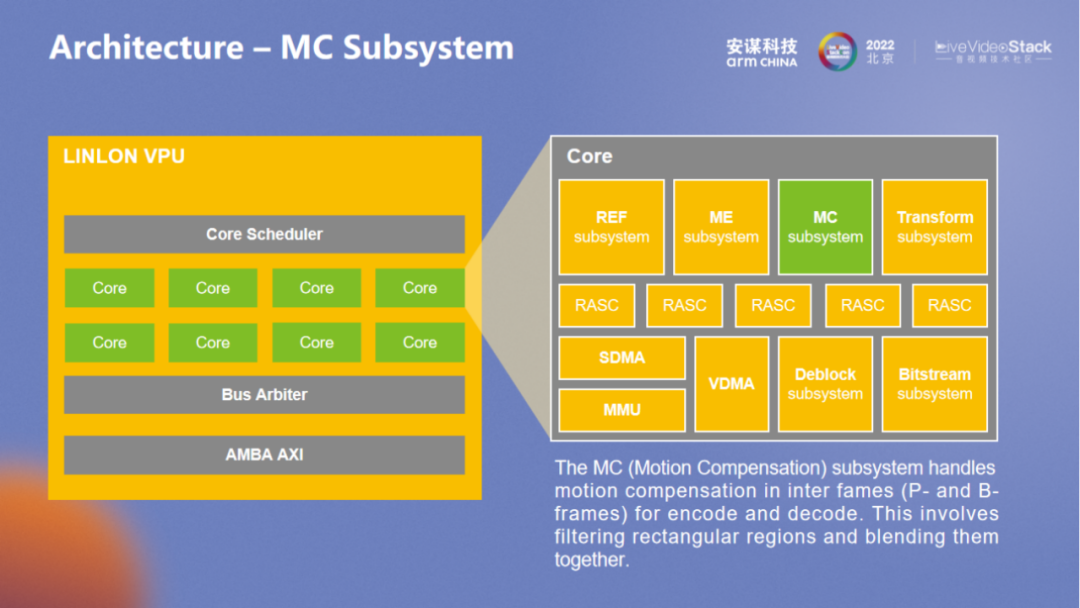
尽管 MC 较为标准,但对于硬件的实现也较为灵活。
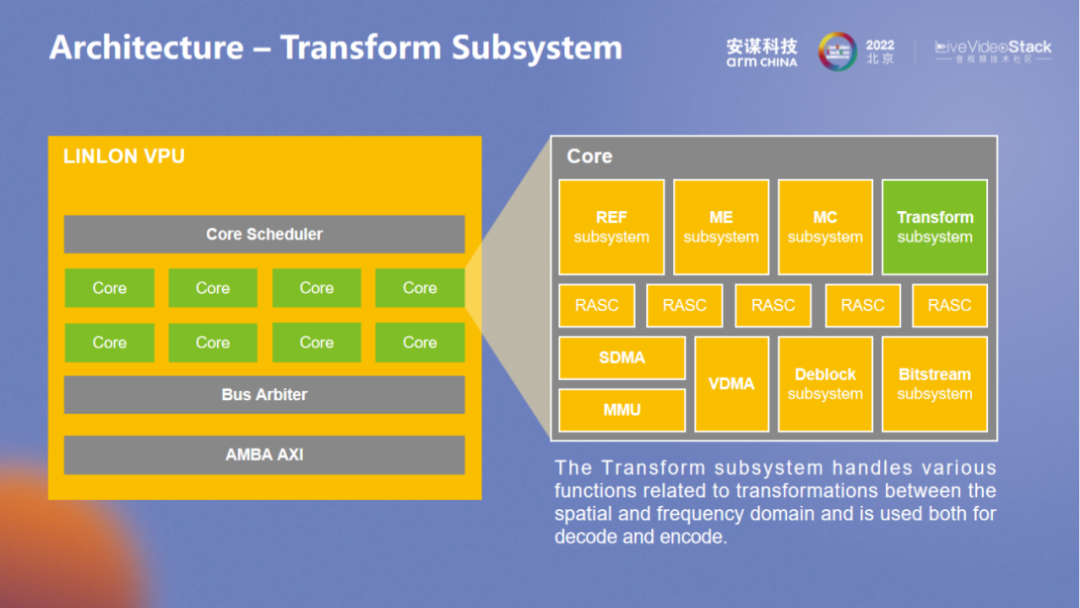
Transform 在这里主要负责所有的变换,融合了不同的格式,也可以通过参数控制。
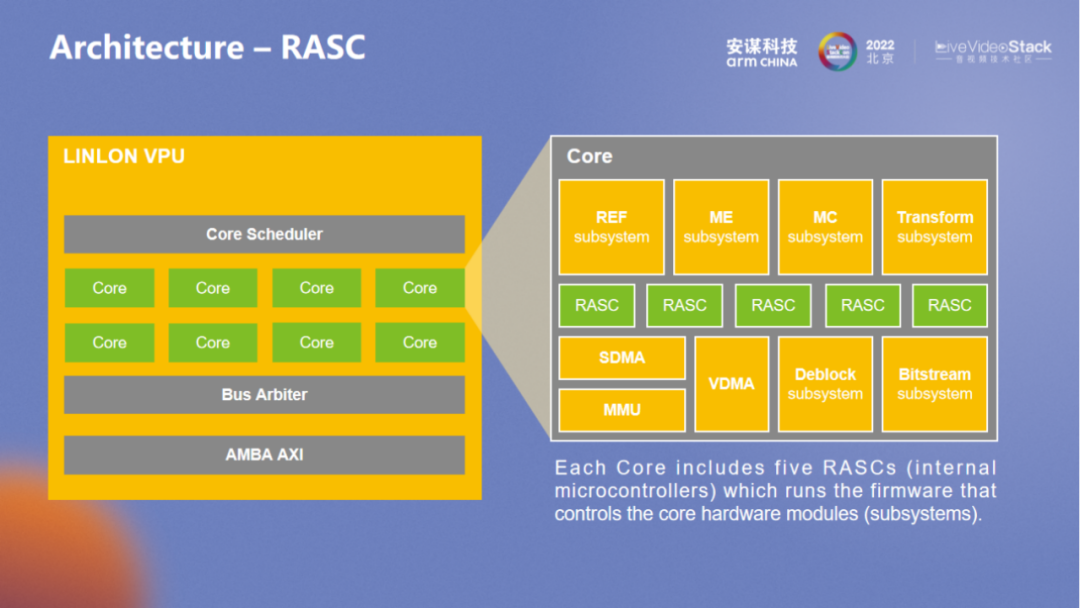
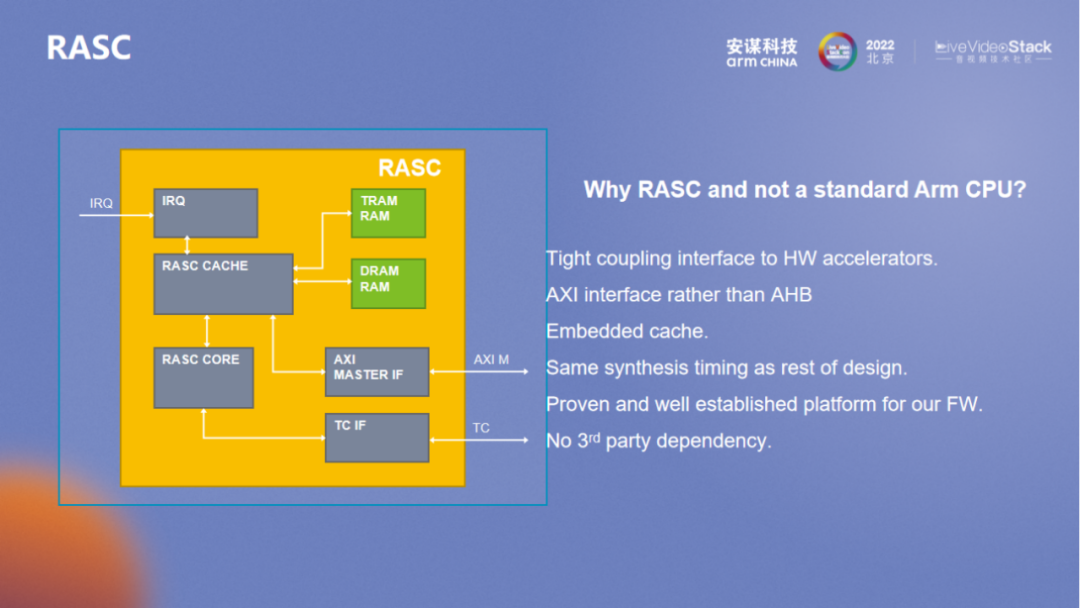
RASC 主要负责整体的管理,数据流也是核间的 IPC 所控制管理的,具有较高的灵活调度性,可避免硬件本身的风险。RASC 的设计比较考验整体的设计能力,“玲珑” VPU 采用了一个小的 MCU,基本上所有的代码和数据都在 ram 里,缓存也与其它同类产品有所区别,我们拥有外部模块的快速访问接口。
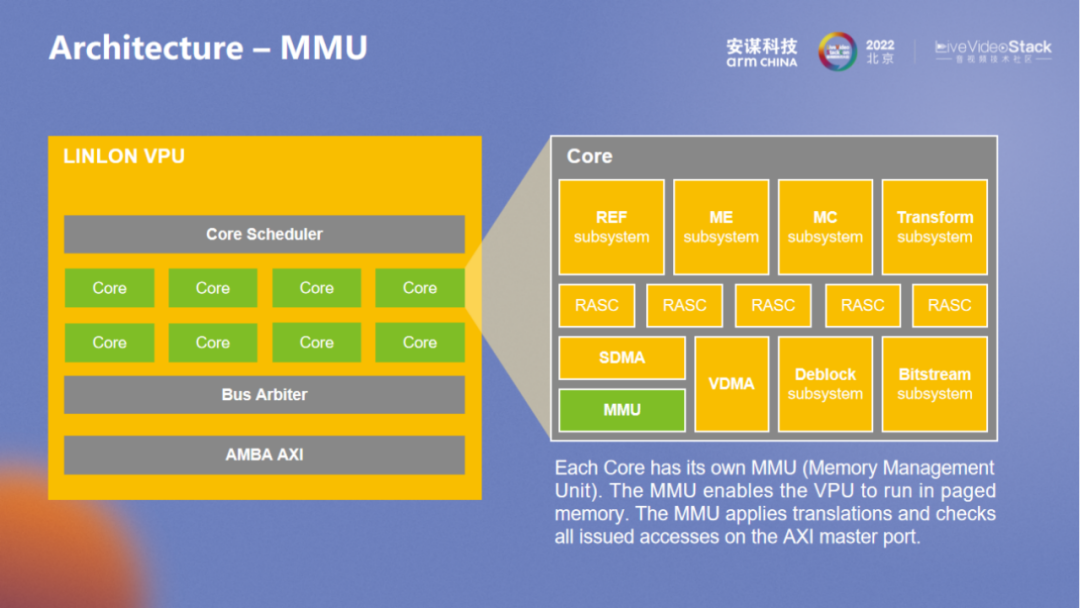
MMU 整体考量方向包括多路和安全,多路本身就需要完整的内存层面的隔离,MMU VA32bit 和 PA40bit,基本上可以满足所有场景的需求。
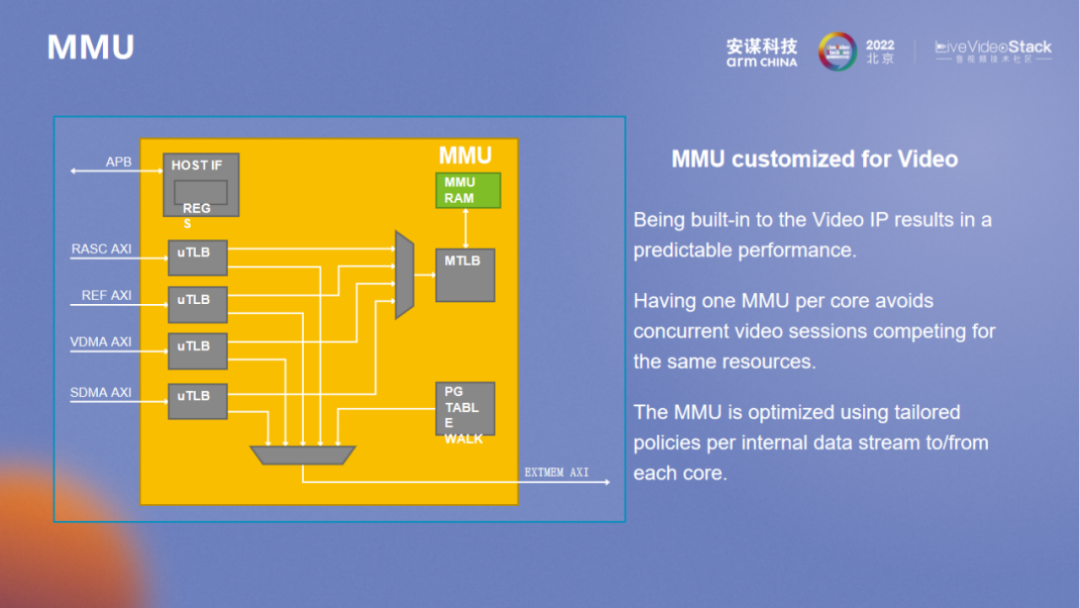
在属性管理方面, protect、可执行等方面属性与 SMMU 类似,但与 Arm SMMU 整体架构不同,此处 MMU 更像是 GPU 内的 MMU,想要应对每个处理单元的访问,每个 uTLB 都应该有所配置,Micro uTLB 和 PTW 也都有相应的优化。
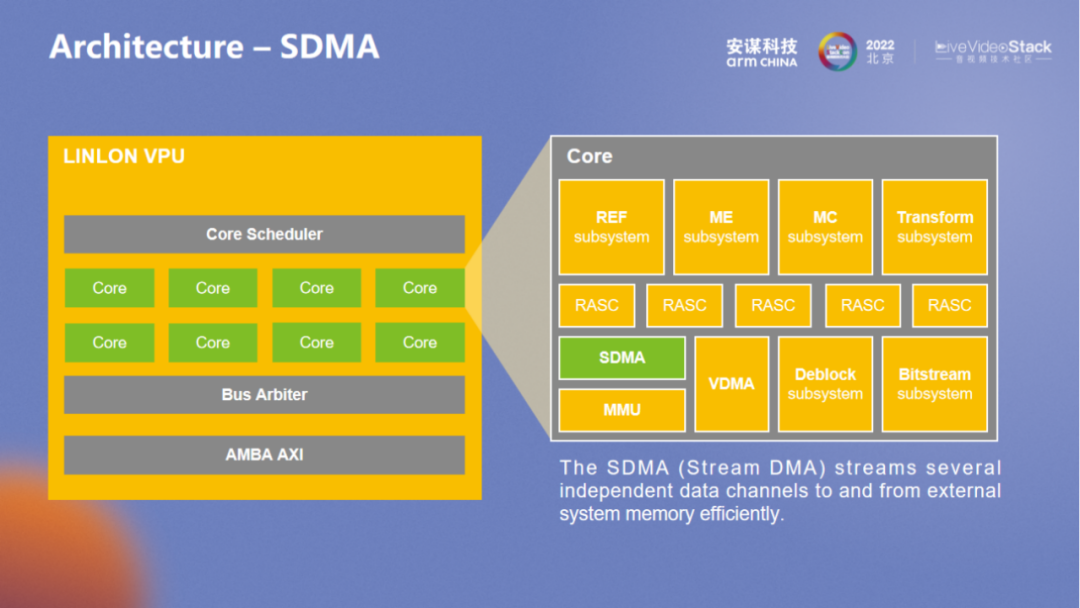
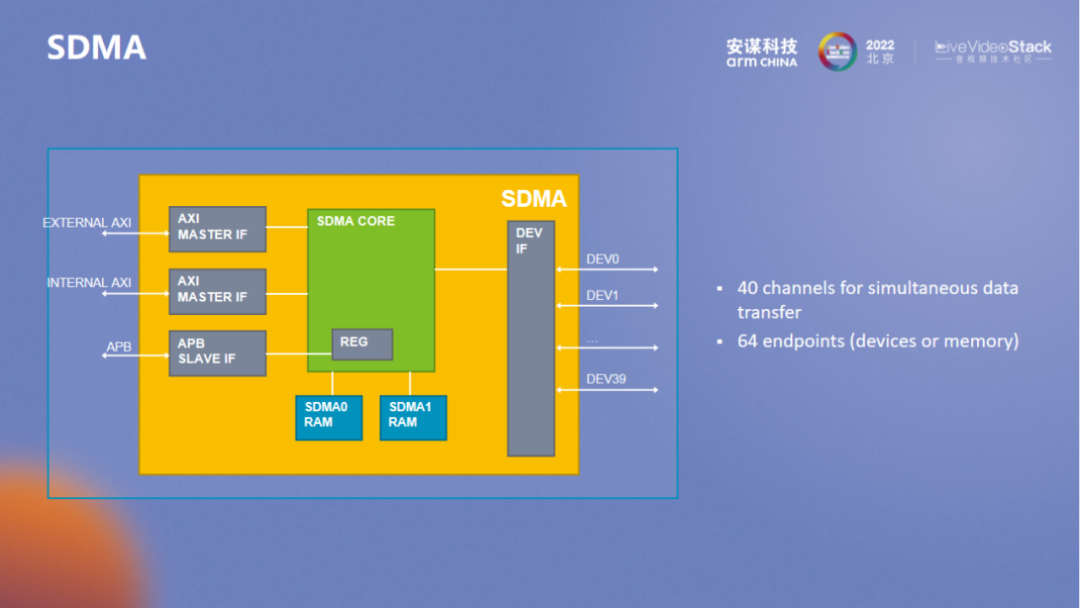
SDMA 是一个更为标准化的 DMA。除了 bitstream 之外,还要应对多个硬件加速单元控制结构之间的传输。所以 “玲珑” VPU 在硬件加速层面有很多细节处理,用以满足整体系统层面的优化。
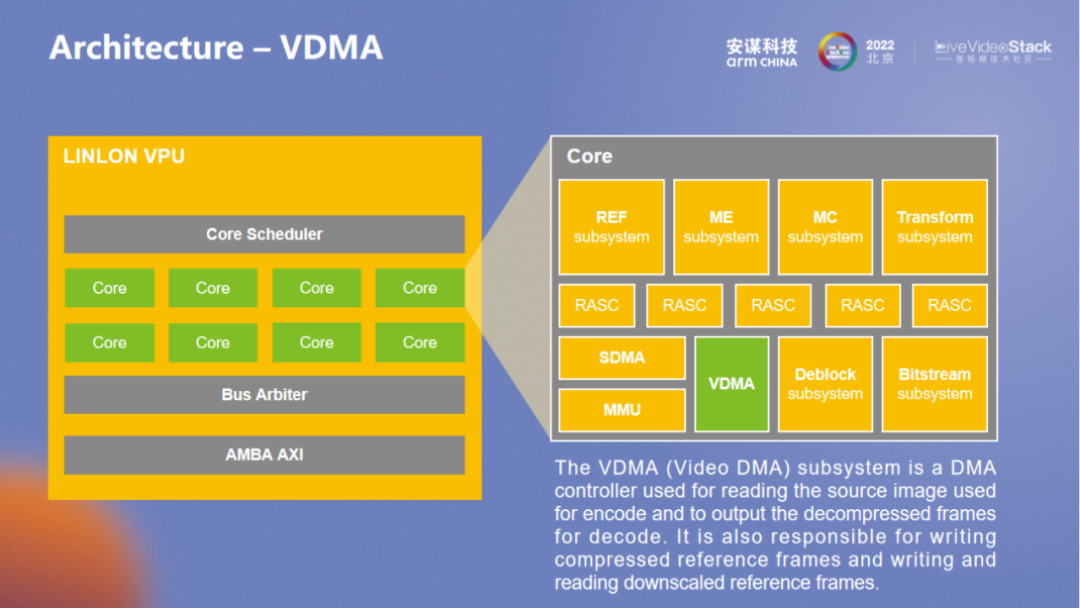
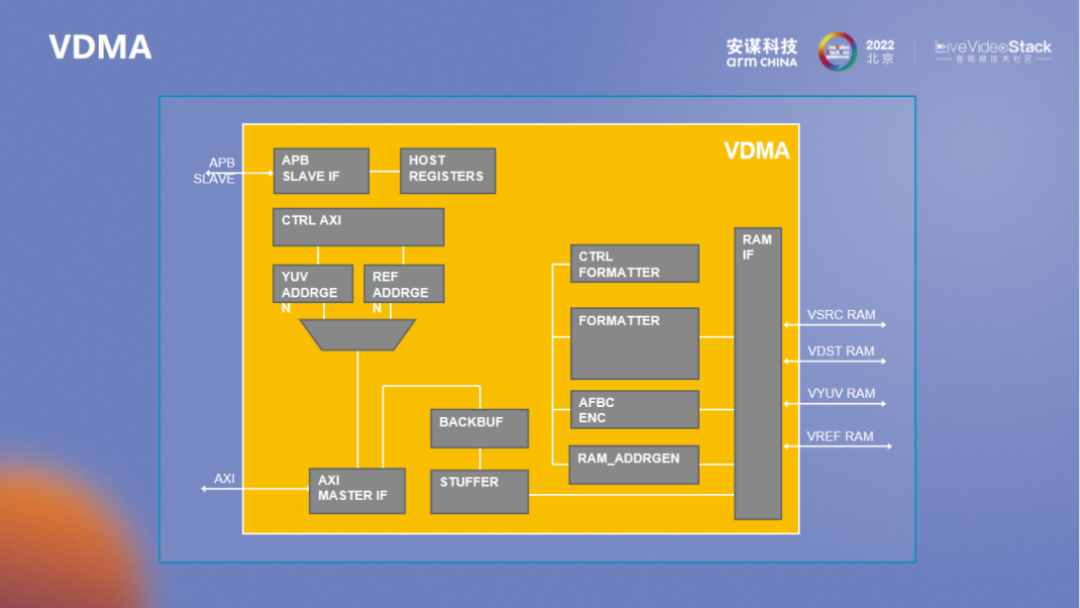
Frame 级别的控制管理都是由 VDMA 进行的。可以看到与 FORMATTER 相关的前处理都在 FORMATTER 里进行,前后处理也有各自的数据通路。最新一代的 “玲珑” VPU 要比图中所示增加了更多新的功能,前后处理层面也有更多的扩展。
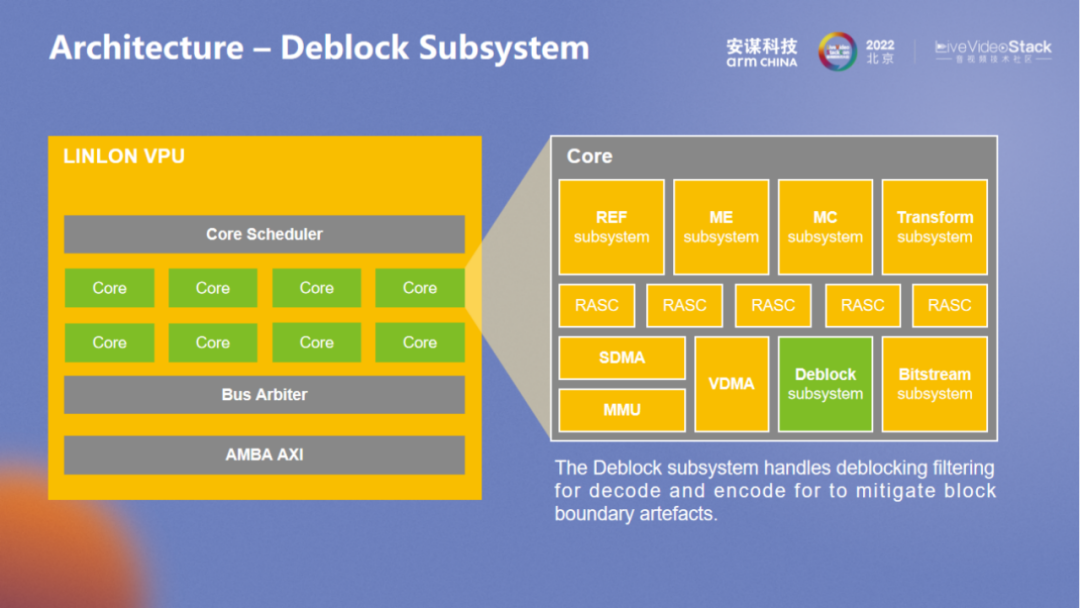
Deblock 是滤波的模块,用以应对不同格式 filter 的需求。
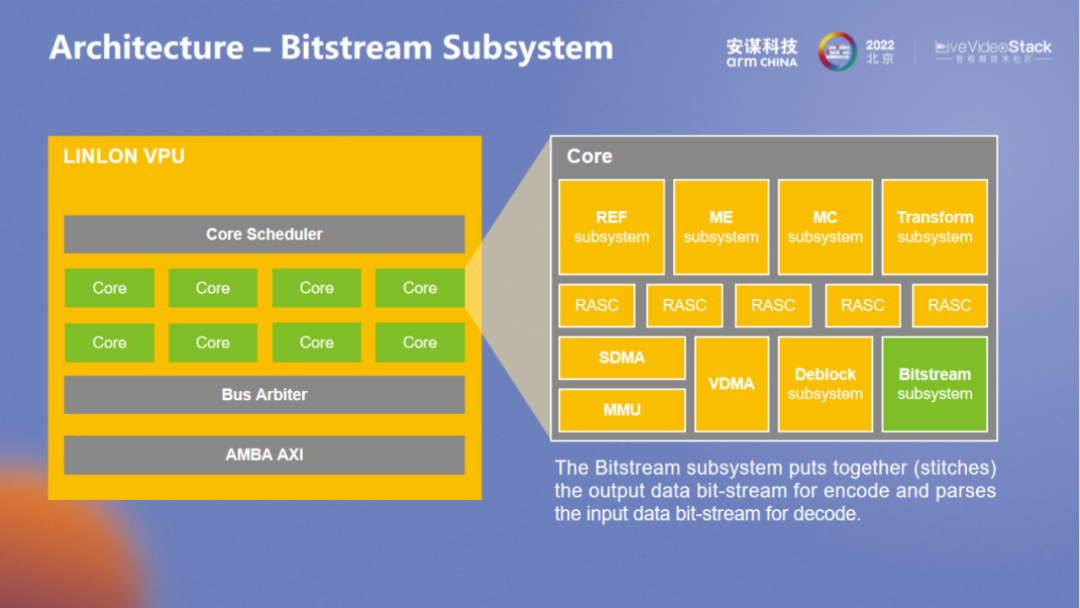
Bitstream 是编码解码码流处理模块,也是用于应对不同格式。在系统层面的 Bitstream 会相对独立,在系统层面划分为 “和流相关” 或 “和 frame 相关”,硬件控制会在系统层面进行两步划分,无论是编码还是解码,都要先 MB 在级别的划分。
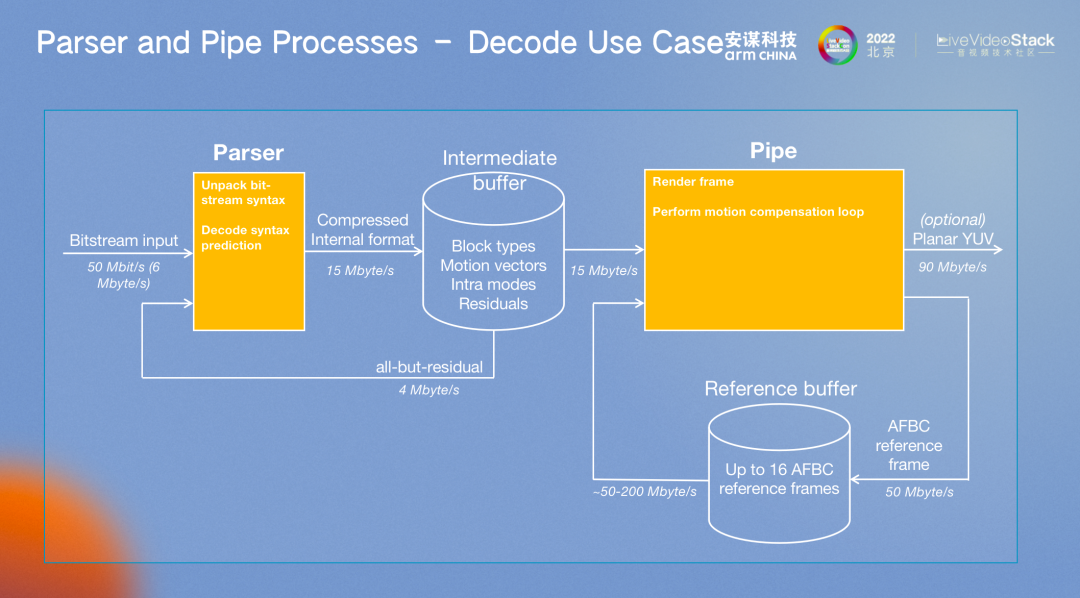
这张图是解码的基本程序,码流、MB、MV 等信息都会进行保存。
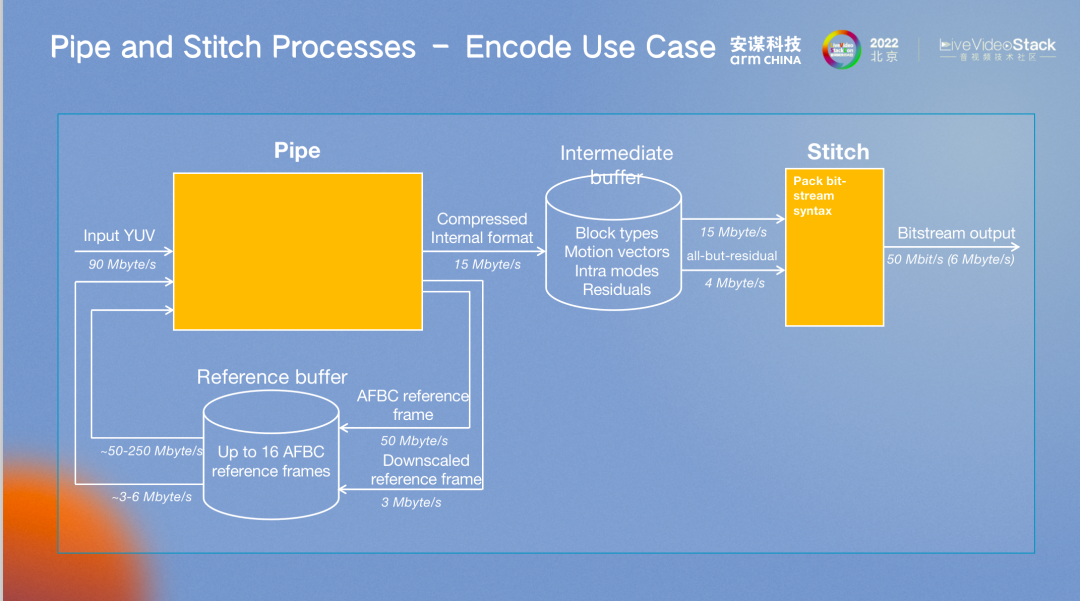
编码过程也与解码过程类似。以上是本次的分享,谢谢大家!

LiveVideoStackCon 2023 上海讲师招募中
LiveVideoStackCon 是每个人的舞台,如果你在团队、公司中独当一面,在某一领域或技术拥有多年实践,并热衷于技术交流,欢迎申请成为 LiveVideoStackCon 的讲师。请提交演讲内容至邮箱:speaker@livevideostack.com。

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







