翻译 | Argus
技术审校 | 曾凯
本文来自Amazon Science Blog,作者为Sathya Balakrishnan、Ihsan Ozcelik。
影音探索 #008#
用于检测宏块损坏、音频失真和音视频同步错误的检测器是Prime Video的三个质量保证工具。
流媒体视频在录制、编码、打包或传输过程中可能会出现缺陷,因此大多数订阅视频服务(如亚马逊Prime Video)都会不断评估其流媒体内容的质量。
人工内容审查(称为人眼主观测试,eyes-on-glass testing)无法实现规模化,而且它自身也具备很多挑战,例如审查者对质量看法的差异。业内更常见的是使用数字信号处理来检测视频信号中的异常情况,这些异常情况经常与缺陷相关。
三年前,为了验证新的应用版本或编码配置文件的离线更改,Prime Video的视频质量分析(Video Quality Analysis ,VQA)小组开始使用机器学习来识别多种设备(如游戏机、电视和机顶盒)所获取的内容中的缺陷。最近,我们将同一技术应用到了实时质量监测数千个频道和实时事件,以及大规模分析新的点播内容等问题上。
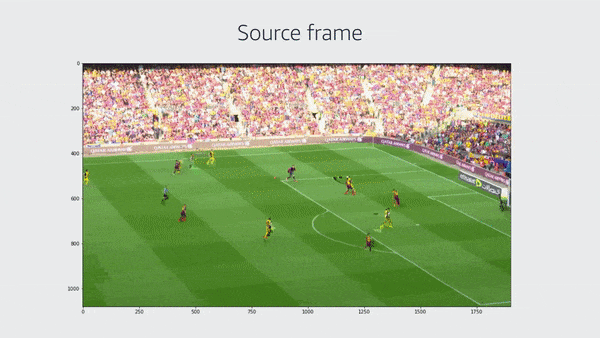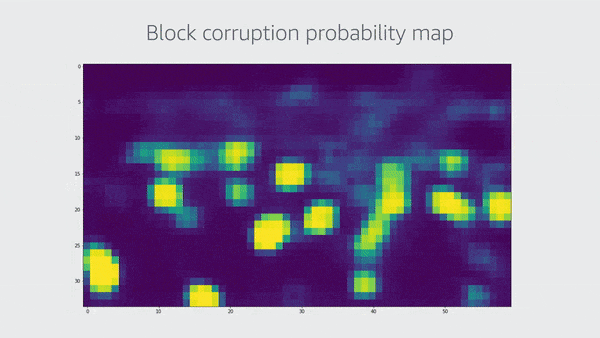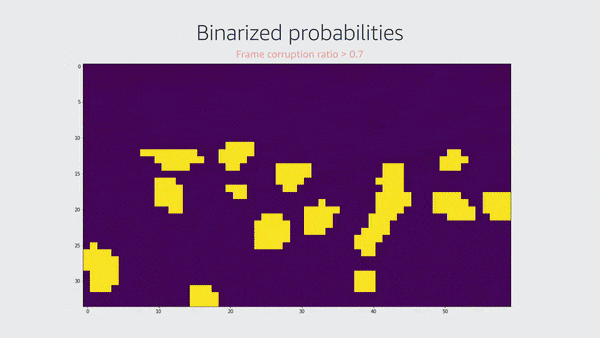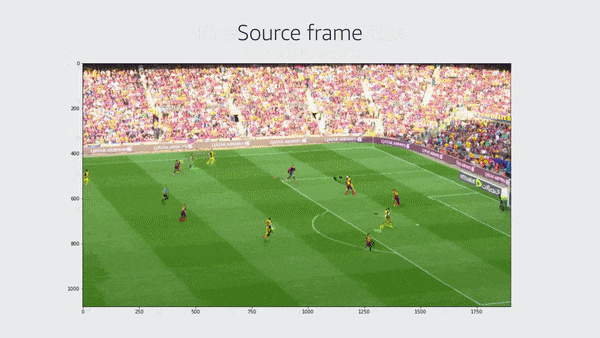
亚马逊Prime Video宏块损坏检测器的初始版本使用残差神经网络来生成表示特定图像位置损坏概率的指示图,将该图二进制化,并计算损坏区域和总图像区域之间的面积比率。
我们的VQA团队训练计算机视觉模型,以观察视频并发现可能损害用户观看体验的问题,如块状帧、意外黑帧和音频噪音。这使我们能够处理数以万计的直播与点播视频。
我们面临的一个有趣的挑战是,由于Prime Video产品中视听缺陷的发生率极低,所以训练数据中缺乏正面案例。我们用一个模拟原始内容缺陷的数据集来应对这一挑战。在使用这个数据集开发检测器之后,我们通过对一组实际缺陷进行测试来验证检测器能否用于实际的线上所生产的内容。
示例:我们如何将音频咔哒声加入纯净音频

纯净音频的波形
纯净音频

添加了咔哒声的音频波形
添加了咔哒声的受损音频
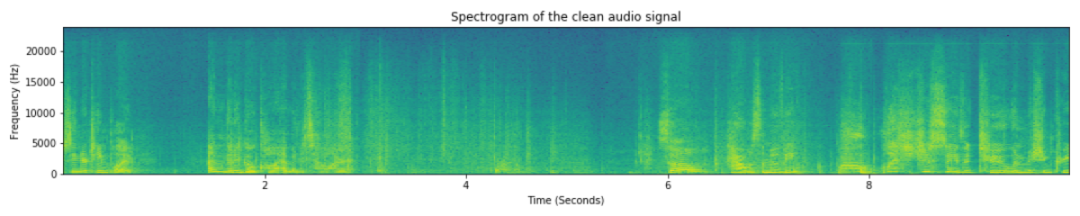
纯净音频的频谱图
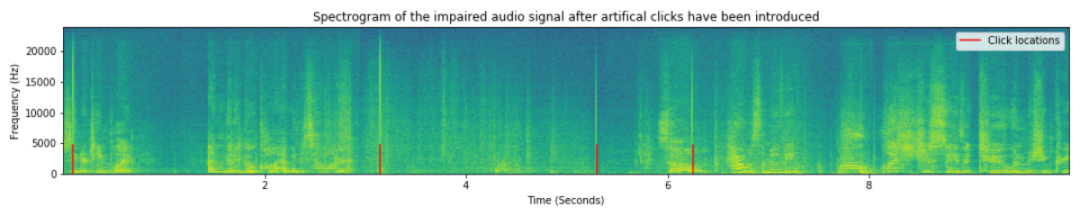
添加了咔哒声的音频频谱图
我们已经为18种不同类型的缺陷开发了检测器,包括视频画面停滞和卡顿、视频撕裂、音频和视频之间的不同步,以及字幕质量问题。下面,我们重点看一下三种缺陷:宏块损坏、音频失真和音视频同步问题。
宏块损坏(Block corruption)
使用数字信号处理进行质量分析的一个缺点是,它可能难以区分某些类型的真实内容和有缺陷的内容。例如,对信号处理器来说,人群中的场景或运动量大的场景可能看起来像有宏块损坏的场景。在这种情况下,传输障碍导致帧内像素块的位移,或导致像素块都使用相同的色值。
宏块损坏的示例
为了检测宏块损坏,我们使用了一个残差神经网络,这种网络的设计使较高的块层(block layer)可以明确纠正下面块层所遗漏的错误(残差)。我们将ResNet18[1]神经网络的最后一层替换为1x1卷积(神经网络图中的conv6)。
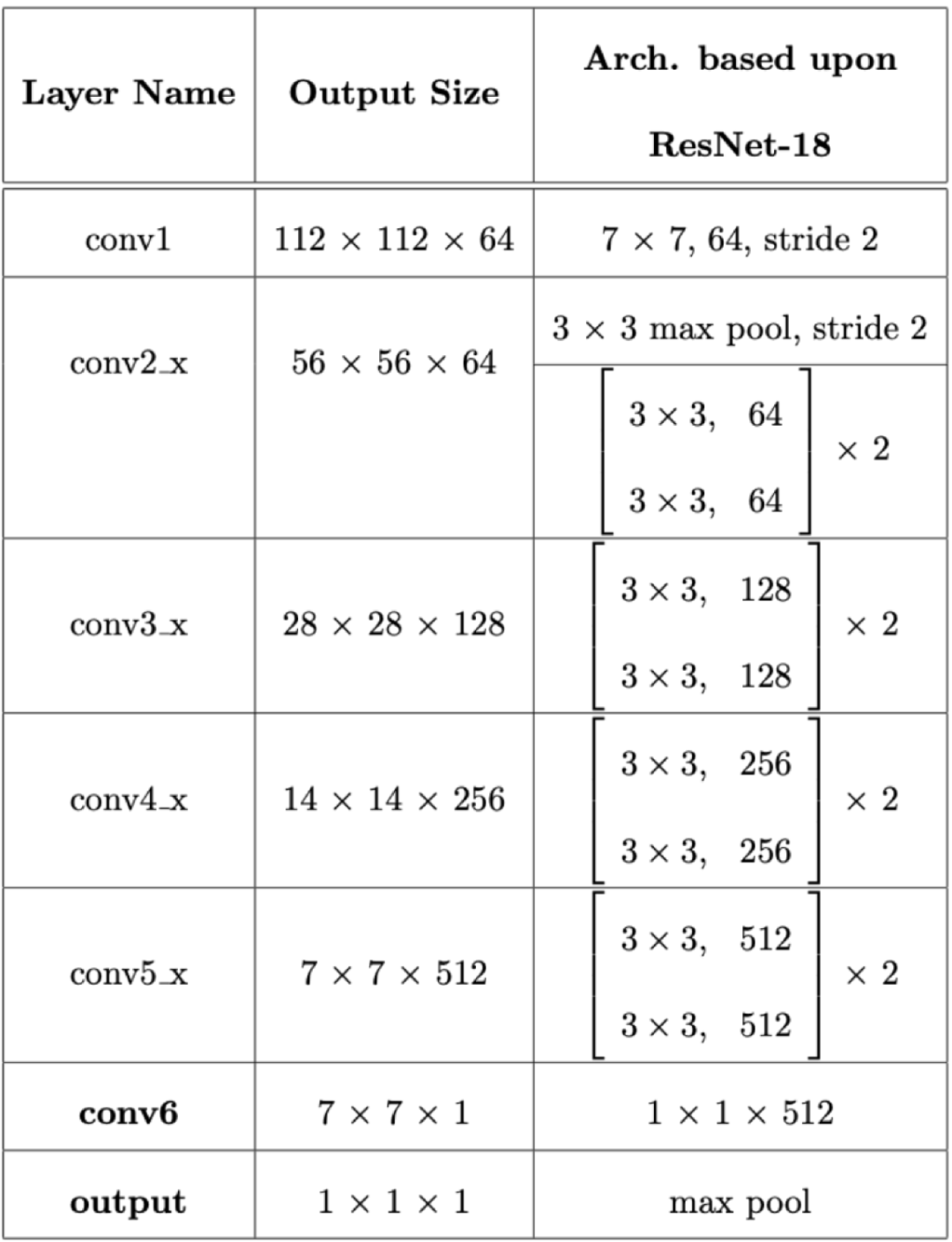
宏块损坏检测器架构
这一层的输出是一个二维图,其中每个元素都是特定图像区域中宏块损坏的概率。这个二维图取决于输入图像的大小。在该图中,一个224 x 224 x 3的图像传递给神经网络,输出是一个7 x 7的二维图。在下面的例子中,我们将一张高清图像传给神经网络,结果输出的是34 x 60像素的二维图。
在这个工具的初始版本中,我们对二维图进行了二进制化处理,并计算出损坏面积的比率:
corruptionArea = areaPositive/totalArea
如果这个比率超过了某个阈值(事实证明0.07很有效),那么我们就把这一帧标记为有宏块损坏。(见上面的动画)
然而,在该工具的当前版本中,我们将决策函数移动到模型中,因此它是与特征提取一起学习的。
音频失真检测(Audio artifact detection)
“音频失真”是音频信号中不需要的声音,它可能是通过录音过程或数据压缩引入的。在后一种情况下,它相当于音频中一个损坏的宏块。然而,有时其他创造性的原因也会引入音频失真。
为了检测视频中的音频失真,我们使用了一个无参考模型,这意味着在训练期间,它无法获得纯净音频作为比较标准。该模型基于预先训练的音频神经网络,将一秒钟的音频片段分类为无缺陷、嗡嗡声、嘶嘶声、音频失真或音频咔嗒声。
目前,该模型在我们专有的模拟数据集上达到了0.986的平衡准确率(balanced accuracy)。关于该模型的更多信息可以在我们的论文《使用预训练的音频神经网络检测音频人工无参考模型》(A no-reference model for detecting audio artifacts using pretrained audio neural networks)中找到,我们在今年的IEEE计算机视觉应用冬季会议上发表了这篇文章[2]。
带有失真音频的视频示例
音视频同步检测(Audio/Video sync detection)
另一个常见的质量问题是音视频同步或唇音同步缺陷,即音频与视频不一致。直播、接收和播放过程中产生的问题会使音频和视频不同步。
为了检测唇音同步缺陷,我们开发了一个检测器——我们称之为LipSync(基于牛津大学的SyncNet架构[3])。
LipSync管道的输入是一个四秒钟的视频片段。它被传递给一个镜头检测模型,用于识别镜头边界;然后传递给用于识别每一帧中人脸的人脸检测模型;再传递给用于识别连续帧中属于同一人脸的人脸跟踪模型。
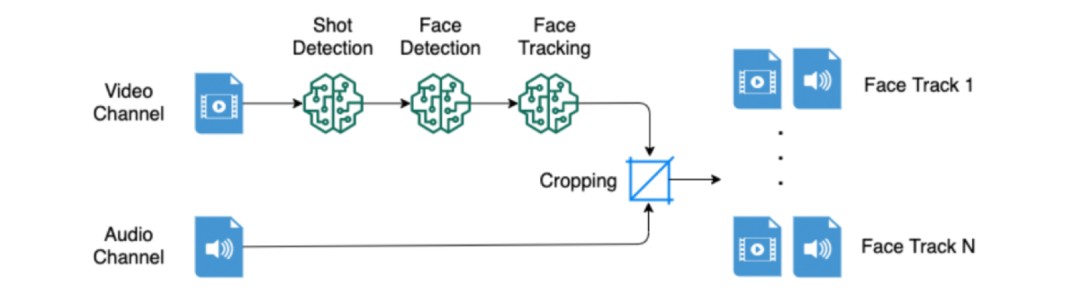
提取人脸轨迹的预处理管道:以单个人脸为中心的四秒钟片段
人脸跟踪模型的输出(被称为人脸轨迹)和相关的音频然后传递给SyncNet模型,该模型汇总整个人脸轨迹以决定该片段是否同步、不同步或不确定,这意味着要么没有检测到人脸/人脸轨迹,要么有相同数量的同步和不同步的预测结果。
未来工作
以上这些是我们工具库中的一些精选检测器。在2022年,我们将继续努力完善和改进我们的算法。在正在进行的工作中,我们正在使用主动学习(active learning,通过算法选择信息特别有价值的训练实例)来不断地重新训练我们部署的模型。
为了生成合成数据集,我们正在研究EditGan[4],这是一种新方法,可以更精确地控制生成式对抗网络(GAN)的输出。我们还在使用我们定制的AWS云原生应用程序和SageMaker实现来扩展我们的缺陷检测器,以监测所有实时事件和视频信道。
注释:
1.https://arxiv.org/pdf/1512.03385.pdf
3.https://www.robots.ox.ac.uk/~vgg/publications/2016/Chung16a/chung16a.pdf
4.https://proceedings.neurips.cc/paper/2021/file/880610aa9f9de9ea7c545169c716f477-Paper.pdf
原文链接:
https://www.amazon.science/blog/how-prime-video-uses-machine-learning-to-ensure-video-quality
编辑:Alex
封面图片来自Unsplash,by Aditya Chinchure

@2017-2024 LiveVideoStack版权所有. 京ICP备20010033号-1  京公网安备 11010502042092号
京公网安备 11010502042092号







